BGP Refresher
BGP Overview
It's a Path vector routing protocol, it's the Defacto standard on the Internet for inter AS(Autonomous system) routing. BGP is a classless routing protocol, supports prefix routing, regardless of the class definitions of IpV4 addressing. Classless means that the subnet mask for an IP address need not be the default mask as specified in Classful addressing.
Intra-AS(e.g. OSPF): can focus on performance
Inter-AS(BGP): policy may dominate over performance
It uses AS Path (vector) which is a series of AS no.s to prevent inter domain routing loops. An AS is a set of routers that operate under the same administrative authority
A Cisco router running BGP could belong to only one AS. The IOS will only allow one BGP routing process to run on a router.
BGP uses TCP, while interior routing protocols like OSPF and EIGRP do not use TCP and work directly under IP, for example OSPF is IP protocol 89. BGP runs over TCP and enjoys all the convenience that TCP offers. BGP is just another application layer protocol to the TCP/IP stack.
The BGP routing table
Routers maintain a separate BGP routing table in addition to the main IP routing table
It contains the list of routes that could be advertised to BGP Peers
BGP routes are based on it's own set of attributes like AS Path, Local Preference etc., it's Independent of IGP metrics like distance/cost
Cisco command to show the BGP routing table
router# show ip bgp
status code * indicates valid, and > indicates best
BGP will not advertise a route to its EBGP Peer unless it is both valid and best.
BGP routes that are both valid and best will also be added to the IP routing table. So the IP routing table would contain BGP routes that are both best and valid.
NLRI
Network layer reachability information
This is nothing but the term used to covey information that BGP routers exchange with their peers, in the form of 'Update' messages
EBGP and IBGP
These are the two main forms of BGP.
EBGP session exists between a device in one AS and another device in a different AS. They should be physically connected.
By default, EBGP exists between directly connected devices as the TTL is set to 1. If the devices are more than a hop away, then a multi hop EBGP session should be established. EBGP peering is generally between the physical interface's IP addresses. Physical interface peering's advantage is that each AS is prevented from knowing the routing information of the other AS, besides what is received through BGP. the peering interfaces share only a shared ip subnet. EBGP peers advertise routes received from their EBGP or IBGP peers.
IBGP peers with in an AS may not be directly connected, and the sessions are between the loopback addresses. Loopback addresses are used for stability reasons, as they are always alive, unless the route itself dies. As the devices are remote, an IGP other than IBGP is still needed with in the AS. The IGP will maintain reachability between the loopback addresses even if the physical topology changes.
IBGP advertises routes originated locally or that received from EBGP peers, but IBGP doesn't advertise any routes learnt from IBGP as BGP uses ASPATH as loopdetection mechanism, and the AS path isnt changed with in an AS. IBGP sessions cannot rely on IBGP received routing information
IBGP sessions usually use loopback addresses because the underlying interior gateway protocol (igp) normally provides redundant paths between two bgp speakers
When Should we use BGP
single homed customers don't need a dynamic routing protocol, they can configure a static default route towards their ISP, and ISP uses a static route vice versa.
when they are multiple upstream connections from multi homed cx.s to single or multi ISPs, BGP may be used.
the provider assigns an aggregate of public IP addresses which could be used by the Cx. when they are the cx. of that SP. these addresses are also called non-portable addresses as they are owned by the SP.
BGP can detect and route around failures in redundant environments (external), but they don't react quickly with in the same AS (Internal), and they often rely on other IGPs to maintain the network operational when failures occur.
multihomed cx.s to a single ISP mostly use non-portable addresses, where as multi homed cx.s with multiple ISPs more likely get portable addresses obtained directly from the RAR (regional address registry).
BGP is not really required when there are multiple connections to the Internet. IGPs like OSPF or EIGRP can easily handle fault tolerance or redundance of outbound traffic.
BGP is also completely unnecessary when there is only one connection to the internet. As that will burden internal router, because internet has more than 1L routes.
BGP should be used when:
1. mul Xns to diff ASs via different SPs
2. mul Xns to diff ASs via same SP
BGP's true benefit lies in controlling inbound traffic to the local AS rather than outbound traffic.
4 BGP entities carry ASNs
there are 4 bgp data entities that carry ASNs
. as_path attribute
. aggregator attribute
. communities attribute
. open message
4 Byte ASN
rfc 4893
4 byte (32 bit) asns have been created to solve the 2 byte as number depletion problem.
a new capability code 65 is used in the open message to neg supp of the 4 byte asn bet two bgp speakers
bgp communities are supported in 4 byte asn environments using a new extended community attribute called the 4-octet AS specific bgp extended community
2 byte (16 bit) as_trans -- 23456 for interoparability with the old BGP imp that do not understand 4 byte asns
detecting that the neighboring AS is the old AS,the local router puts the as_trans to the as_path as a place holder for its own AS and for any other AS numbers appearing on the path
as4_path and as4_aggregator are optional transitive attributes
where as as_path is a well known mandatory attribute
Juniper configuration example:
edit routing-options
set autonomous-system 100000 */4 byte ASN as-plain notation*/
or
set autonomous-system 1.34464 */4 byte ASN as-dot notation*/
BGP Messages
BGP peers exchange the following messages: open, keepalive, update, notification, refresh
the message length will be between 19(just header) and 4096(header+data) Octets (Bytes)
1. Open
...............
Opens TCP connection to the peer and authenticates the sender.
To initiate the BGP session.
contents:
bgp version no. (currently 4, must match between peers), router id, local AS no., BGP Rev no., Keepalive Holdtime, etc...
2. Keep Alive
..........................
sent every 60 s by default, if a router doesn't receive keep alive from its neighbor for a Hold-Time Period (180s by default), that peer is declared as dead. keepalives are sent by TCP not by BGP. Keeps connection alive in the absence of UPDATES, also Acknowledges OPEN request
3. Updates
.....................
exchange routing updates between peers. advertises new path (or withdraws old)
4. Notification
..........................
sent by a router to its existing peer when there is a fatal error condition, and the BGP peering session will be torn down and reset. It reports errors in the previous msg, and is also used to close connection
BGP States
Unlike other dynamic routing protocols, BGP neighboring should only be defined manually.
no automatic neighborship discovery.
BGP uses TCP as its transport protocol (port 179)
BGP considers its peers to be idle until a TCP connection is established between them
3 TCP states (idle, connect, active)
3 BGP states (open sent, open confirm, established)
BGP Peer Session States (6)
-----------------------------------------
This refers to the state of the router with its peer
As a BGP peer session is forming, it will pass through several states, this process is known as the BGP FSM (Finite State Machine)
1. Idle
............
The Initial BGP State
All incoming BGP connections are refused. A start event is required for the local system (router) to initialize bgp resources and prepare for a TCP connection with the other router.
2. Connect
.....................
BGP process in the router, waits for a TCP connection with the peer.
If successful, OPEN message is sent.
If unsuccessful, the router restarts the ConnectRetry timer, listens for a connection initiated by the peer, the session is changed to Active State.
3. Active
.................
BGP attempts to initiate a TCP connection with the remote peer.
If successful (TCP 3way HandshakE), OPEN message is sent.
If unsuccessful, the session will be changed back to connect state, once the ConnectRetry timer expires.
If fails, it remains in active state
If a peer session is stuck in an Active state, potential problems can include:
physical connectivity issues, no IP connectivity (no route to host), an incorrect neighbor statement, or an ACL filtering TCP port 179.
4. OpenSent
.........................
TCP connection is established, after which the Open Message is sent.
In the OpenSent state, the router is waiting for a reply Open message from its Peer.
If an open message is received with errors, it reverts back to the idle state, and the process continues. If an open message is received with no errors, the local device sends a keep alive message.
5. OpenConfirm
...............................
Once the reply open message is recived, the router will send Keep Alive message.
The session is in OpenConfirm state, and the router is awaiting a reply KeepAlive message from its peer.
if the peer sends a keepalive msg, then the local device gets into established state. if it sends a notification, then the local device reverts back to idle. if it doesnt send keepalive with in the hold timer, then the local device sends a notification and gets back to idle.
6. Established
............................
Reply Keep alive message is recieved from the peer.
BGP session is completely established.
The router will now send routing information to its peer in the form of UPDATE messages.
once BGP forms neighborship, it exchanges complete routing table with the peer.
later on, only changes in the routing table are forwarded to peers.
if an update or keepalive is received with in the hold timer, the timer is again restarted. if an update or keep alive isnt received with in the hold timer, the local router sends a keep alive message and restarts the timer. the update message contains routing information which may be either received or ignored depending on the routing policy.
if a notification is sent or received, the router changes its state to idle.
Example BGP Initial configuration, authentication, timers etc. on Cisco
1. Start the BGP process and specify the ASN
routerB(config)# router bgp 100
2. Specify the neighbor
iBGP
routerB(config-router)# neighbor 10.1.1.1 remote-as 100
eBGP
routerB(config-router)# neighbor 172.16.1.2 remote-as 900
neighbor 192.168.100.2 version 4 -- bgp v4
3. For stability purposes, the source interface used to generate updates to a particular neighbor can be specified
routerB(config-router)# neighbor 172.16.1.2 update-source lo0
Though eBGP assumes that external peers are one hop away, using lo0 as a source interface, puts routerB two hops away from routerC. Although Router B and Router C are directly connected physically.
4. use ebg-multihop to discover the ebg neighbor as its 2 hops away
routerC(config-router)# neighbor 1.1.1.1 ebgp-multihop 2
the default no. of hops if not specified, is 255.
5. to authenticate updates between two bgp peers
router(config-router)# neighbor 172.16.1.2 password <anypassword>
6. configure global or neighbor specific keepalive and hold timers, the default values are 60 and 180s
if the configured timers vary between peers, then the smallest values among them would be considered.
these values need not be equal among peers
routerB(config-router)# timers bgp 30 90 /* global */
routerB(config-router)# neighbor 172.16.1.2 timers 30 90 /* per neighbor */
Cisco command to view neighbors
1. Viewing BGP Neighbors
routerB# show ip bgp neighbors
2. View the status of a specific BGP neighbor
routerB# show ip bgp neighbors 172.16.1.2
sh ip bgp neighbors
this command displays:
the bgp neighbor address
remote ASN
BGP Version no.
neighbor's router id (highest ip address on the loopback interface, or the physical interface if loopback interface doesnt exist)
keep alive time
keep alive hold time
table version etc...
eg. table version = 4, this should be same on all the peers
if table version keeps on increasing, it means some route might be flapping, causing the routing table to be updated
6pe
rfc 4798 - 6pe is a tech that provides interconnectivity of ipv6 sites over the isp's ipv4 mpls cloud
6pe is similar to mpls l3 vpn where customer packets are transported over the isp network in mpls packets
PEs are dual-stack routers running ipv6 towards an ipv6 island and ipv4 towards the core. the interface between the edge router of the ipv6 island and the 6pe router is a native ipv6 interface
pe to pe sessions must be multiprotocol sessions supporting ipv4 and ipv6 families
PEs (a 6pe asbr router) convey family labeledipv6 unicast between them over ipv4 bgp sessions
we must configure appropriate export policies on the PE router to share routing information between bgp and other protocols
BGP synchronization
BGP Synchronization is disabled by default.
BGP follows a synchronization rule that states all routers including non bgp ones in a transit AS, must learn of a route, before BGP advertises it to an external peer.
scenario
ra (AS 100) -> rb--rc[non bgp]-rd (AS 200) -> re(AS300)
let network x is advertised by Router A to Router B via EBGP.
RouterB sends route X to RouterD via iBGP.
However, a blackhole would exist if Router D then advertises that update (route X) to RouterE.
as Router C would not have the Route X in its routing table. If Router E tries to reach route X, router C will drop the packet.
BGP synchronization rule, if enabled on router D, will make router D to wait until router C learns about route X.
This will be known to router D through an IGP update (such as OSPF) from router C about route X.
BGP Synchronization can be disabled under 2 cicumstances:
1. The local AS is not a transit AS.
2. all routers in the transit AS run iBGP, and are fully meshed.
cisco config.
-------------
router(config)# router bgp 100
router(config-router)# no synchronization
Network statement
3 Ways to originate prefixes:
1. Network statements
2. Aggregate address statements
3. Redistributing an IGP into BGP
Note: prefix + attributes(Local Preference, AS Path etc.) = “route”
The route must be in the routing table before BGP will advertise the network to an eBGP peer.
This is a fundamental BGP rule.
network command could be used under router bgp hierarchy
to indicate which networks should be advertised using bgp
but the networks should already be present in the routing table of the router
The network statement could be used to inject any route from the local AS to an eBGP peer, not just connected routes but also other routes learnt from IGP. The network statement isnt used to specify which interfaces should run BGP.
cisco config.
------------------
RouterB(config)# router bgp 100
RouterB(config-router)# neighbor 172.16.1.2 remote-as 900
RouterB(config-router)# network 10.5.0.0 255.255.0.0
eg:
router(config-router)# network 10.0.0.0
this can either include a specific mask or the default classful mask will be applied
Full Mesh Requirement
---------------------
iBGP peering doesnt have any hop limit, but is dependent on the IGP running in the AS. By default, all iBGP peers must be fully meshed, with in an AS.
IBGP routers can advertise routes from their EBGP peers, to another IBGP peers
IBGP routers can also advertise routes originated by themselves to another IBGP peers
But they donot advertise routes received from an IBGP peer to another IBGP peer
This is to prevent loops and IBGP peers do not update the AS path with an AS
the AS path is only updated by EBGP peers
for eg. if R1 receives an EBGP route from the ISP, it advertises it to R2, but R2 can not advertise the same to R3
so R3 lacks info about the ISP. Here R1,R2,R3 all belong to the same AS
This enforces full mush requirement with in an AS.
Full mesh requirement doesnt mean physical full mesh, as the peering is only between Loopback addresses. and the physical reachability is mostly maintained by an IGP other than IBGP.
<BGP Route Reflectors>
Route Reflectors (RFC 2796)
iBGP with in an AS requires full mesh peering.
for eg. if there are 6 routers, it would require 6*(6-1)/2 = 15 iBGP sessions. cisco recommends RR technique to alleviate full mesh.
we use route reflectors which peers with iBGP speakers and forwards routes from other peers to route reflector clients. route reflector clients peer only with the route reflector server, thus decreasing the no. of iBGP sessions resulting in less bandwidth and CPU usage, as the neighbor connections are few.
BGP updates will flow from the server to the clients, without the clients having to interact with each other. route reflector clients can not forward iBGP routes to route reflector server unless specified to do so. the rr server and rr client forms a cluster and more than one cluster can exist in an AS.
Reflection rule
----------------------
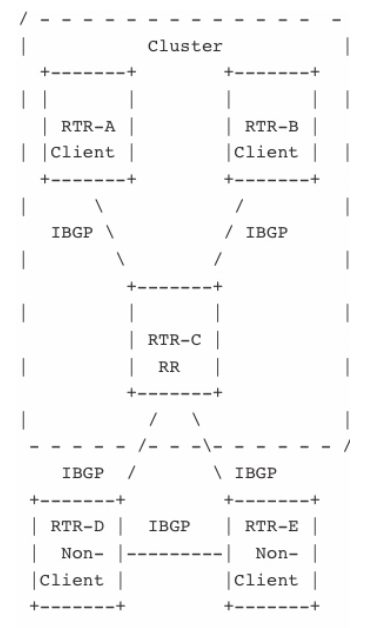
When an RR receives a route from an IBGP peer, it selects the best
path based on its path selection rule. After the best path is
selected, it must do the following depending on the type of the peer
it is receiving the best path from:
1) A Route from a Non-Client IBGP peer
Reflect to all the Clients.
2) A Route from a Client peer
Reflect to all the Non-Client peers and also to the Client
peers. (Hence the Client peers are not required to be fully
meshed.)
originator_id attribute (optional nontransitive)
------------------------------------------------------------------------
ORIGINATOR_ID is a new optional, non-transitive BGP attribute of Type
code 9. This attribute is 4 bytes long and it will be created by a RR
in reflecting a route. This attribute will carry the ROUTER_ID of
the originator of the route in the local AS. A BGP speaker should not
create an ORIGINATOR_ID attribute if one already exists. A router
which recognizes the ORIGINATOR_ID attribute should ignore a route
received with its ROUTER_ID as the ORIGINATOR_ID.
cluster_list attribute (optional nontransitive)
--------------------------------------------------------------------
Usually a cluster of clients will have a single RR. In that case, the
cluster will be identified by the ROUTER_ID of the RR. However, this
represents a single point of failure so to make it possible to have
multiple RRs in the same cluster, all RRs in the same cluster can be
configured with a 4-byte CLUSTER_ID example 1.1.1.1 so that an RR can discard routes
from other RRs in the same cluster.
Cluster-list is a new optional, non-transitive BGP attribute of Type
code 10. It is a sequence of CLUSTER_ID values representing the
reflection path that the route has passed.
Cluster ID is a 4 Byte value, used to prevent loops when more than one rr cluster exists in an AS. The cluster-list contains the list of cluster_id s indicating the path through which the route has reflected. the cluster_id is also the bgp id of the rr. if the rr receives an update with no cluster_id, it adds its cluster_id... if the message contains a cluster_list with out the cluster id of the rr, it prepends it cluster_id to the list. if the list contains the rr's cluster_id, it ignores the update avoiding loop
Config.
----------
All RR specific configuration takes place on the server
routerA(config)# router bgp 100
routerA(config-router)# neighbor 10.2.1.2 remote-as 100
routerA(config-router)# neighbor 10.2.1.2 route-reflector-client *routerD*
routerA(config-router)# neighbor 10.1.1.2 remote-as 100
routerA(config-router)# neighbor 10.1.1.2 route-reflector-client *routerB*
BGP Confederations
this is also to alleviate full mesh iBGP, using sub ASs with in an AS
routerB(config)# router bgp 888 /* this is the sub-AS */
routerB(config-router)# bgp confederation identifier 300 /* this is the parent AS */
routerB(config-router)# bgp confederation peer 777
routerB(config-router)# neighbor 10.1.1.1 remote-as 777 /* iBGP neighbor with parent AS 300 */
routerB(config-router)# neighbor 172.16.1.2 remote-as 500 /* eBGP neighbor router C */
routerC(config)# router bgp 500
routerC(config-router)# neighbor 172.16.1.1 remote-as 300 /* form peer with routerB */
routerC isnt aware of routerB's confederation status.
BGP Peer Groups
this is used to send updates to all routers with in a peer group at once, rather than individually. and thus saves processor / memory resources. useful in the case of a route reflector server.
all neighboring parameters will be applied to the peering group itself
router(config)# router bgp 200
router(config-router)# neighbor MYPEERGROUP peer-group
router(config-router)# neighbor MYPEERGROUP remote-as 200
router(config-router)# neighbor MYPEERGROUP update-source lo0
router(config-router)# neighbor MYPEERGROUP route-reflector-client
router(config-router)# neighbor 10.10.1.1 peer-group MYPEERGROUP *to define routers in the group*
router(config-router)# neighbor 10.10.2.2 peer-gorup MYPEERGROUP
router(config-router)# neighbor 10.10.3.3 peer-group MYPEERGROUP
all members of a group must exclusively be iBGP or eBGP peers. mix of eBGP and iBGP peers is not allowed.
outbound route filtering via dl, rmap, etc. must be identical on all members of the group. inbound route filtering can still be applied on a per-neighbor basis.
BGP Attributes
RFC1771
Attributes are used to find the best path, which may not be the shortest path
Classes:
1. Well Known Mandatory e.g: AS Path, origin, next-hop
2. Well known discretionary-Must be supported, not necessarily be incl. in the update message
e.g: Local Preference, Atomic Aggregate
3. Optional transitive-support optional, but if supported, must be included e.g: community, aggregator, implies a non compliant BGP router will forward the unsupported attribute unchanged, when sending updates to peers.
4. Optional nontransitive-support optional, ignored if not added in the update e.g: MED, Cluster List, Originator ID, implies a non compliant BGP router strips out the unsupported attribute, when sending updates to the peers.
BGP Route Selection Summary
Before the BGP router installs a route it checks:
1. next-hop is reachable
2. there are no loops (AS path doesnt contain its AS no.)
3. if multiple routes exist to the same destination prefix, the lower route preference will be selected
4. if routes have the same route preference, the following BGP path selection process will be considered:
The BGP path selection process:
------------------------------------------------
If BGP contains multiple routes to the same destination, it compares the routes in pairs, starting with the newest entries listed higher in the routing table, and working towards the oldest entries listed lower in the table.
The attributes of each route pair are compared in a specific order:
1. Higher Local Preference - to route traffic through a preferred edge router in the AS
2. Shortest AS path - often a tie breaker
3. Lowest Origin Code 0<1<2 iGP<eGP<incomplete
4. lowest MED value - if multiple paths between the two ASs
5. routes learned through EBGP peer preferred over that learned through IBGP peer, for EBGP skip to step9
6. only for iBGP:
a. inet.3 routes are preferred over inet.0 routes
b. if inet.3 and inet.0 routes have same preference, inet.3 will still be chosen
c. if multiple routes with the same preference exist in the same routing table, often due to traffic-engineering bgp-igp knob in mpls, then the physical next hops of an instance with more hops is installed.
7. route from the peer with the lowest router id is preferred
8. shortest cluster length
9. only for EBGP: route from the peer with the lowest router id is preferred
Simple path selection based on 3 important attributes (LAN: LP, ASPATH, NextHop)
- Highest Local preference value
- Shortest AS-PATH
- Closest NEXT-HOP router
from router alley:
order
...........
1. weight (cisco only) - highest weight will be considered
2. local preference - highest local preference wins
3. locally originated - is the next-hop 0.0.0.0
4. AS-Path - shortest AS Path will be considered
5. Origin Code - lowest origin value wins 0<1<2 iGP<eGP<incomplete
6. MED - lowest MED
7. BGP route type - eBGP routes preferred over iBGP
8. Age of route - oldest preferred
9. Router ID -- RID of the router which originated the route initially, lowest ID preferred.
10. Peer IP address - lowest Peer IP.
when applying attributes, weight and LP are applied to inbound routes, dictating the best outbound path
AS-Path and MED are applied to outbound routes, dictating the best inbound path.
BGP Weight Attribute (cisco propreitary)
This is cisco propreitory and is never passed on to BGP neighbors.
This is of local significance to the router only.
similar to local preference, provides a local weight to determine the best path for outbound traffic.
Value ranges from 0 - 65535
Default value is 32768 for routes originated on the local router
and is 0 for all other routes.
Weight is only applied to inbound routes, dictating the best outbound path.
a single weight value could be applied to all routes from a neighbor
routerA(config)# router bgp 100
routerA(config-router)# neighbor 10.1.1.2 weight 200
weight could also be applied to selective routes coming from a neighbor
1. define the specific route
routerA(config)# ip prefix-list MYLIST 192.168.1.0/24
2. define route map to set weight 200
routerA(config)# route-map WEIGHT permit 10
routerA(config-route-map)# match ip address prefix-list MYLIST
routerA(config-route-map)# set weight 200
3. apply the route map
routerA(config)# router bgp 100
routerA(config)# neighbor 10.1.1.2 route-map WEIGHT in /* in for inbound routes coming from neighbor */
Local preference (higher is best)
This is used only with IBGP, the designated peer adds a local preference to all received routes, by configuring the BGP protocol hierarchy or the routing-policy hierarchy. This is to direct outbound traffic through a specific peer with in an AS. if the local preference value is configured in both the BGP protocol and routing-policy hierarchies, the routing-policy configuration will be preferred. Higher local preference will be preferred when selecting a route, 100 is the default value.
Local preference is applied to inbound external routes, unlike weight, it is passed in an update to iBGP peers.
highest value wins
used when multiple paths exists, to choose the best path to exit the AS.
32 bit value, 0 to 4294967295
default LP is 100
1. can be set globally to all inbound external routes
--------------------------------------------------------------------------
routerB(config)# router bgp 100
routerB(config-router)# bgp default local-preference 200
routerD(config-router)# router bgp 100
routerD(config-router)# bgp default local-preference 300
as LP is flood across to all iBGP peers, routers A and B will now prefer the route through router D to reach any destination outside the local AS.
2. lp can also be applied on a per route basis
-------------------------------------------------------------------
routerD(config)# ip prefix-list 192.168.1.0/24
routerD(config)# route-map PREFERENCE
routerD(config-route-map)# match ip address prefix-list MYLIST
routerD(config-route-map)# set local-preference 300
routerD(config)# router bgp 100
routerD(config-router)# neighbor 172.17.1.2 remotes-as 900
routerD(config-router)# neighbor 172.17.1.2 route-map PREFERENCE in
BGP AS-Path Prepend / Filtering using Regular Expressions
AS-Path prepend or filter could be applied to the outgoing routes dictating the best inbound path
1. Prepend - to make the route less desirable
--------------------------------------------------------------------
routerB(config)# access-list 5 permit 10.5.0.0 0.0.255.255
routerB(config)# route-map ASPREPEND permit 10
routerB(config-route-map)# match ip address 5
routerB(config-route-map)# set as-path prepend 200 200
routerB(config)# router bgp 100
routerB(config-router)# neighbor 172.16.1.2 route-map ASPREPEND out
the artificial AS-Path information is not added to a route until it is advertised to an eBGP peer.
if we check router C's bgp database table it will have two entries for 10.5/16 one through router D (*>) and other through router B (* inflated), it will chose route via routerD as through B will have a bigger AS Path.
2. Filtering
----------------
Regular AS string expressions:
----------------------------------------------
^ start, $ end, . any one char, ? any one char including none, + any one or more charactesrs, * any one or more characters including none, - serves the functionality of virtually all of the above
examples
^100_ = learned from AS 100
_100$ = originated from AS 100
^$ = originated locally
.* = everything
_100_ = any instance of AS 100
to configure RouterF to only accept routes that originated from AS 100
define access list
routerF(config)# ip as-path access-list 15 permit _100$
define route map and call the access list 15
routerF(config)# route-map ASFILTER permit 10
routerF(config)# match as-path 15
set the route map for inbound routes in bgp
routerF(config)# router bgp 50
routerF(config)# neighbor 10.5.1.1 remote-as 100
routerF(config)# neighbor 10.5.1.1 route-map ASFILTER in
sample command to see what routes will match a regular expression
routerF# sh ip bgp regexp _100$
filter-list
--------------
router bgp 24084
!
address-family ipv4
neighbor 59.160.150.129 filter-list 10 out
ip as-path access-list 10 permit ^$ --- this is used to advertise all locally generated routes
MED(Multi Exit Discriminator) (lesser is best)
provides a preference to eBGP peers to a specific inbound router.
by default, MED is set on a router when multiple upstream connections exist between the router's AS to a different AS.
the MED value is set on the edge routers forming the physical connection with the remote AS. the local router with the lowest MED will be chosen, and the remote router receiving the route will transfer back updates using the same link/path.
if MED is not specified, junos will take it as 0.
MED is configured either under protocols BGP hierarchy using metric-out statement
or under routing-policy then statement, specifying the action as metric with the value.
applied to outbound routes, dictating the best inbound path
default cisco MED is 0
the MED is identified as the BGP metric when viewing the BGP routing table
lower metric is preferred.
we can assign the med on routerB to 200 so that router D will be preferred for inbound traffic
routerB(config)# access-list 5 permit 10.5.0.0 0.0.255.255
routerB(config)# route-map SETMED permit 10
routerB(config-route-map)# match ip address 5
routerB(config-route-map)# set metric 200
routerB(config)# router bgp 100
routerB(config-router)# neighbor 172.16.1.2 route-map SETMED out
above config forces AS 900 to prefer the path through router C (med 0) for the prefix 10.5/16
when we enter show ip bgp
med is shown by the metric column
med is adv only from one as to another and not further that
so in this case from as100 to as900 and not further, metric will be reset to 0 if the route is advertised beyond this AS
BGP's method of route selection
--------------------------------
when multiple routes are received for the same prefix, bgp compares them in pairs starting from newest to oldest entries, which could sometimes lead to suboptimal routing
two MED related commands on AS 900 (in scenario) are used to alleviate this situation
deterministic-med (multiple routes from the same AS)
always-compare-med (multiple routes from different ASs)
MED values would be compared regardless of the order in which the routes are received
routerE(config)# router bgp 900
routerE(config)# bgp deterministic-med
disable by default, above command ensures med values are compared while doing best path selection comparing routes
if enabled, all the routers should in the AS should have this turned ON
routerE(config)# bgp always-compare-med
Setting igp metric as bgp med
------------------------------
*metric-type internal*
routerB(config)# access-list 1 permit 10.5.0.0 0.0.255.255
routerB(config)# route-map IGPMETRIC permit 10
routerB(config)# match ip address 1
routerB(config)# set metric-type internal
routerB(config)# router bgp 100
routerB(config)# neighbor 172.17.1.2 route-map IGPMETRIC out
sets MED as the link state cost metric of OSPF (if igp running is OSPF), for 10.5/16 prefix
Community
tags groups that share common characteristics into communities.
used to tag a group of destination prefixes.
communities are set, added, or deleted in a routing policy under the edit->policy options hierarchy
bgp communities are supported in 4 byte asn environments using a new extended community attribute called the 4-octet as specific bgp extended commuunity
communities are used to tag routes, so that specific policies may be applied to them
3 types of community formats
----------------------------
Decimal - default
Hexadecimal
ASN:No. - ip bgp community new-format, command to be used to enable this format
ASN : No. (Generic Identifier Number) -- 16 bit + 16 bit
4 Well Known Communities
-------------------------
No-Export -- to EBGP -- set community no-export
No-advertise -- to IBGP or EBGP -- set community no-advertise
Internet -- advertised out of local AS -- set community internet
Local-AS -- not advertised to EBGP or confederation peers with in the AS -- set community local-as
the community attribute will not be sent by default, to a peer
routerB(config-router)# neighbor 172.16.1.2 send-community
example - 10.5/16 routes not to be sent out of AS 900
-----------------------------------------------------
step1 acl
routerB(config)# access-list 1 permit 10.5.0.0 0.0.255.255
step2 route-map
routerB(config)# route-map NOEXPCOMM permit 10
routerB(config)# match ip address 1
routerB(config)# set community no-export
step3 applying route map to bgp peer
routerB (config)# router bgp 100
routerB(config)# neighbor 172.16.1.2 remote-as 900
routerB(config)# neighbor 172.16.1.2 send-community
routerB(config)# neighbor 172.16.1.2 route-map NOEXPCOMM out
the above route 10.5/16 will be received by router C and it sends it to all its IBGP peers
but doesnt send beyond the AS to any EBGP peer
modifications:
--------------
set community no-export will simply over write the old community values
additive key word may be used to append values
*set community no-export additive*
bgp communities are supported in 4 byte asn environments using a new extended community attribute called the 4-octet as specific bgp extended commuunity
BGP Summarization
routes redistributed into BGP are automatically summarized by default
router bgp 100
no auto-summary -- to disable auto-summary
manual summary
--------------
for four routes redistributed into bgp - 172.16/24, 172.16.1/24, 172.16.2/24, and 172.16.3/24
summary route be created as 172.16.0/22
*note that auto-summary would lead to 172.16/16 instead (classful)*
routerB(config)# router bgp 100
routerB(config-router)# aggregate-address 172.16.0.0 255.255.252.0
BGP will send both 172.16/22 as well as the 4 specific routes
routerB(config-router)# aggregate-address 172.16.0.0 255.255.252.0 summary-only
the above command makes BGP not send the 4 specific routes
summarize specific routes
-------------------------
to create a specific route only for 2 prefixes - 172.16/24 and 172.16.1/24
and ignore the other two
step1 acl
routerB(config)# access-list 1 permit 172.16.0.0 0.0.0.255
routerB(config)# access-list 1 permit 172.16.1.0 0.0.0.255
step2 route-map
routerB(config)# route-map SUPPRESSMAP permit 10
routerB(config-route-map)# match ip address 1
step3 apply route-map as suppress map
routerB(config)# router bgp 100
routerB(config-router)# aggregate-address 172.16.0.0 255.255.252.0 summary-only suppress SUPRESSMAP
as-set to make the summary routes retain the AS path info
----------------------------------------------------------
routerB(config-router)# aggregate-address 172.16.0.0 255.255.252.0 summary-only suppress SUPRESSMAP as-set
BGP Route Damping / Dampening RFC 2439
---------------------------------------------------------------------
What is Route Flapping / Flapping:
phenomenon where routes (in few cases thousands) will appear and disappear rapidly
due to link fail and restore repeatedly in short duration of time
link flaps up and down
causes more processing power/bandwidth consumption
because all the update/withdrawn msgs are propagated to peers, and effects cascade quickly
BGP is quite unstable with Route Flapping due to:
1. BGP maintains separate tables in memory for inbound and outbound traffic per peer basis
2. BGP propagates information on an as-needed basis
one intermittently failing link can adversely affect a whole network
to avoid protocol churn, Damping is employed which causes routers to ignore routes that are frequently changing
causes of route instability:
1. Bad Links/Circuits
2. IGP instability (due to bag links causing igp failure, when raw IGP routes are advertised into bgp)
3. Bad Routing Policies
4. Link Congestion
5. Old routers with software bugs, insufficient processing power, insufficent memory, network upgrades and maintenance
Damipng is ignored on iBGP sessions, applied on EBGP sessions (thousands of routes)
BGP has no reachability information of its own, and relies on IGP to resolve next hops
once damping is enabled, the local router maintains a database of instability
some ISPs no longer use route damping
damping Figure of Merit (point value) -- penatly
------------------------------------------------
1000 is the deault penalty in cisco and juniper
0 for new route (default value), 1000 for withdrawn route, 1000 for readvertised route, 500 when path attribute is changed
points decay (reduce) at a certain rate (half-life)
when figure of merit > configurable cutoff (suppressed) threshold, route becomes unusable (isnt advertised and isnt used locally as well)
suppress value should be <= merit ceiling value
setting route-dampening on cisco for two prefixes 10.1/16 and 10.2/16
---------------------------------------------------------------------
step1 prefix-list
router(config)# ip prefix-list DAMPLIST seq 10 10.1.0.0/16
router(config)# ip prefix-list DAMPLIST seq 20 10.2.0.0/16
step2 route-map
router(config)# route-map DAMPMAP permit 10
router(config-route-map)# match ip address prefix-list DAMPLIST
router(config-route-map)# set dampening 15 750 2000 60
step3 applying route-map
router(config)# bgp 100
router(config-router)# bgp dampening route-map DAMPMAP
15minutues => half-life timer, penalty decays by half every 15 minutes
750 => bottom threshold, if penalty < 750, it is no longer suppressed
2000 => top threshold, if penalty > 2000 its suppressed
60 => route can not be suppressed for more than 60 minutes
BGP Next-Hop-Self
IBGP routers donot change the next-hop address in the update message as its sent to the IBGP peer, by default.
for example, let R1 and R2 belong to the same AS.
let R1 receives a route from its EBGP peer, the isp router.
The isp router will advertise a route with the next-hop which is its physical interface/address connected to R1.
now R1 will advertise the above received route to its IBGP peer R2, but with out changing the next-hop.
the above is the default behavior.
R2 can not install that route because the next-hop address is the ISP router's physical interface and R2 doesnt have any connectivity to it.
solution
--------
so now R2 should reach the ISP router either through static routing or through an IGP like OSPF.
or R1 must send the routes by altering the next-hop, which is reachable to R2.
however using next-hop self action under a policy in R1 would be a better option, as it has some advantages
this would make R1 advertise the received route from the ISP router, to R2 by changing the next-hop value from the ISP router's physical interface address, to R1's loopback address which has formed the peering with R2's loopback address through IBGP.
so now as R2 receives the route, it would install it, as it has reachability to R1's loopback
Changing the Next-Hop
---------------------
configure R1 so that R2 could reach ISP A (AS 65501)
----------------------------------------------------
user@R1# edit policy-options
user@R1# edit policy-statemnt next-hop-self-policy
user@R1# set term alter-next-hop then next-hop self
user@R1# edit protocols bgp group int-65503
user@R1# set export next-hop-self-policy
configure R2 so that R1 could reach ISP B (AS 65502)
----------------------------------------------------
user@R2# set policy-options policy-statement next-hop-self-policy term alter-next-hop then next-hop self
user@R2# set protocols bgp group int-65003 export next-hop-self-policy
JunOS recommends that we always apply the next-hop self policy as an export policy to the internal peers or to the BGP group
to which those peers belong. Improper application of a next-hop self policy can cause suboptimal routing or result in
hidden routes.
When defining a next-hop self policy, ensure that we do not include the accept action in conjunction with the next-hop
action. Using the accept action in conjunction with the next-hop action effectively matches all routes, BGP and otherwise,
and advertises those routes to the configured IBGP peers.
cisco command
-------------
sh ip bgp on router A would show the route for 192.168.1.0 as * => because next hop 172.16.1.2 (router C) isnt reachable
routerB(config)# router bgp 100
routerB(config)# neighbor 10.1.1.1 remote-as 100
routerB(config)# neighbor 10.2.1.2 remote-as 100
routerB(config)# neighbor 10.1.1.1 next-hop-self
routerB(config)# neighbor 10.2.1.2 next-hop-self
before sending an update to ibgp neighbors, we can used nhspolicy on the asbr or igp passive on the asbr's external interface
BGP Backdoor
in certain cases a particular destination may be reachable via both EBGP (AD 20) and IGP such as OSPF (AD 110)
by default, EBGP would be chosen, implies sub-optimal routing
*we don't have to reach an internal network via outside (EBGP)*
network address backdoor command is used to prefer IGP path over EBGP
alternate way is to modify the AD value of BGP
command: distance bgp external-distance (def 20) internal-distance (def 200) local-distance (def 200)
example
router bgp 100
distance bgp 150 210 210
router bgp 100
network 10.5.0.0 mask 255.255.0.0 back door
back door command adjusts the ad value of EBGP from 20 to 200, by default
Maximum Prefix, Fast External Fallover
router bgp 100
neighbor 10.1.1.1 maximum-prefix 10000 -- only 10000 routes can be received from 10.1.1.1
router bgp 200
bgp fast-external-fallover -- globally, to immediately rest an eBGP session if a link connecting two peers go down
per interface basis
int s0/0
ip bgp fast-external-fallover permit
BGP Operational Mode Commands
juniper operational mode commands
---------------------------------
user@router> show bgp summary
user@router> show bgp neighbor
user@router> show bgp group
user@router> show route hidden extensive
user@router> show route protocol bgp
user@router> show route protocol bgp extensive
user@router> show route protocol bgp detail
user@router> show route receive-protocol bgp 172.30.1.2
from the specified neighbor
this actually shows th RIB-In entries before being filtered using any import policy
but this doesnt how ever show hidden routes that are rejected by import policies
user@router> show route receive-protocol bgp 172.30.1.2 hidden
user@router> show route advertised-protocol bgp 172.30.1.2
to the specified neighbor
shows RIB out entries, after applying export policies
cisco operation mode commands
-----------------------------
router# clear ip bgp * -- to clear all bgp sessions
router# clear ip bgp * soft -- to force a resending of routing updates / no bgp session reset
clear ip bgp 192.168.100.2
router# show ip bgp summary -- *to view neighbor table* - list of connections, no. of routes etc..
show ip bgp neighbors
show ip bgp -- forwarding table/database
show ip route -- routing table
show ip route bgp -- bgp routes in the routing table
AS Path:
--------
by default the router at the edge of an AS adds its AS no. to the front of the AS Path, as it transitions between different ASs.
when a bgp router receives an update message, the first action would be to check the AS path, junos performs a verification if the local AS no. is in the path, if so it drops it and the route is not advertised, to avoid loops, as the route would have already crossed that AS no.
BGP Attribute codes
Origin Code 1
AS-Path Code 2
Next Hop Code 3
MED Code 4
LocalPref Code 5
AutAgg Code 6
Aggr Code 7
Comm Code 8
BGP NextHop
up on receiving an update bgp always checks the bgp next hop for reachabiliy. bgp next hops are only changed over ebgp sessions and not over ibgp sessions
next-hop:
---------
the bgp peer which advertises the route, places its address in the next-hop attribute. when the update message reaches the remote peer, the next-hop attribute may be changed to this remote peer's address and then advertised to the next peer only if its an EBGP. by default for IBGP, the next-hop attribute is not changed as the route is re-advertised to other peer, though they can be changed using policy controls.
if a next-hop becomes unreachable, the corresponding hidden route may be viewed by
user@router> show route hidden
or
user@route> show route protocol bgp all
A router chooses prefers a route from the closest next hop router, this refers to hot potato routing. Hot-potato routing is the practice of passing traffic off to another autonomous system as quickly as possible, thus using their network for wide-area transit. Cold-potato routing is the opposite, where the originating autonomous system holds onto the packet until it is as near to the destination as possible.
BGP Numbers
max 200 network entries could be used with BGP v4
cisco ebgp ad 20, ibgp 200, 1 for static, 110 for ospf, 90 for eigrp, 120 for rip, 100 for igrp
cisco prop weight def value 32768, range 0 to 65535
RFC 4271 -- BGP Version 4
TCP 179
cisco Default EBGP TTL 1
BGP Header Size 19 B
Max BGP Msg Size 4096 B
Min BGP Msg Size 19 B, with just header, no data
Keeaplive Msg Size 19 B, coz no data
default local preference is 100
default route prefence of bgp is 170
Well Known Communities RFC 1997
Comuunity Attribute - 32 bit -- ASN:no. 16+16, ASN0 and ASN65535 are restricted
RFC 4360 Extended Community Attribute -- 64 bits -- Tye: ADministrator: no.
rfc 4893 - 4 byte asn
open message capality code for 4 byte asn - 65
2 byte as_trans -- 24356 for interoparability with the old bgp imp that do not understand 4 byte asns
rfc 4798 - 6pe
Well Known
3 standard values:
0xffffff01 - No exprt to other AS
0xffffff02 - no advertise to other BGP peers
oxffffff03 - no export-subconfed, no export to ebgp, confined to sub-as)
RFC 1930 -16 bit ASNs 0 to 65536, private 64512 - 65534
reserved - 0, 56320-64511, 65536
ASN -- 16 bit, 1 to 65535
64512 - 65535 (Internal / Private Use)
RFC 4893 - 32 bit ASNs x.y
reserved - 1.y and 65535.65535
old ASNs are written as 0.y
med default value 0, lower better
Cisco AD Value EBGP 20, IBGP 200
junos idle timeout up to 40 hours
junos holdtimer default 90 seconds, modifying range 20s to 65535 seconds
BGP Route Flap Damping RFC 2439, November 1998
Locally originated
next hop of 0.0.0.0 indicates that the route was locally originated into BGP.
path is empty as the route originated in the AS.
Difference between Import and Export Policies
import policies determine which routes out of the existing ones(RIB In) should be present in the routing table before they are installed in the routing table (RIB-Local)
export policies determine which routes out of the active routes in the local routing table (RIB local) should be forwarded to others (RIB Out)
export policies can only export active routes that are present in rib local, by default, to override this we can use advertise-inactive option to advertise bgp routes that are inactive because of route preference
Origin
the router that advertises a route places the origin attribute in its update message. by default origni will be 0,1, and 2 for IGP, EGP, and Incomplete(not Igp/egp) received routes respectively.(where the actual router received the routes from)
this refers to the origin of the route
i<e<?
in juniper its
0<1<2
0 is most preferred, 2 is least preferred
i refers to igp most probably the routes obtained by the network command
e refers to egp
? refers to incomplete, which is mostly redistribute command for connected, static, or igp routes
when we enter
show ip bgp
the path column shows something like i implying igp origin
or 900? impying 900AS path and incomplete (redistributed)
routes with just origin tag ? and no path implies
ibgp routes whose origin are static/connected
or
local router's static/connected routes redistributed into bgp
routes with just origin tag i and no path implies
ibgp routes whose origin are igp
or
local router's igp routes redistributed into bgp
Reset
Generally BGP couldnt advertise routes that are already sent. Refresh messages are used for soft clearing of BGP sessions, so that routes could be re-advertised. this has specific uses in case of MPLS VPNs.
clear ip bgp *
clear ip bgp 192.168.1.1
--end-of-post--